Une plate-forme centralisée pour les demandes des données de diverses sources, principalement sur les IOC (indicateurs de compromis). Cette plate-forme est en cours de développement et je l’envisage comme suit.
Centralisation
La centralisation des demandes et des réponses externes permet pour :
- * un traitement normalisé des requêtes (limitation du débit, mise en cache, proxys, …)
- * un format de réponse commun (erreur, succès, délais, …)
- * un mécanisme centralisé de mise en cache
- * une liste globale d’IOC ignorés
- * une gestion intégrée des limites et quotas
- * la gestion des secrets
- * tâches d’arrière-plan
- * métriques/logs
- * l’authentification
En ayant tous ces éléments déjà intégrés, la création d’une source est aussi simple que de la configurer et d’écrire le code nécessaire pour corréler les données. Dans mon domaine, j’ai vu de nombreuses façons différentes de traiter cette question, dont la plupart étaient excessivement compliquées en raison des facteurs suivants :
- * la duplication du code
- * d’avoir de multiples microservices déconnectés (même si cela peut sembler une bonne idée, ce n’est pas le cas)
- * de l’absence de centralisation des éléments ci-dessus
Demande de données
Les données (IOC) que vous pouvez rechercher peuvent varier en fonction de leur nature, les plus courantes étant :
- * Adresses IPs
- * Domaines
- * URLs
- * Haches (MD5, SHA1, SHA256, SHA512, TLSH, SSDEEP, …)
- * Noms de fichiers
- * Courriels
- * Noms d’utilisateur
- * Noms
- * Numéros de téléphone
L’agrégateur d’indicateurs n’est pas une plateforme de stockage et de suivi des IOC, mais plutôt une plateforme qui peut être utilisée pour obtenir des informations plus détaillées à leur sujet et disposer d’un endroit centralisé pour stocker les données provenant de diverses sources de données.
Sources
Les sources peuvent varier en forme. Elles peuvent être écrites statiquement en Rust ou dynamiquement en Python ou JavaScript sans avoir besoin de recompiler l’ensemble de l’application. Il peut s’agir
- * d’un service tiers en ligne
- * d’un processus d’IA
- * d’une enquête sur des données OSINT
- * d’une simple recherche dans une base de données
- * …
Puisque les sources ne sont qu’un morceau de code exécuté, votre imagination est votre limite.
Sources intégrées
Les sources intégrées sont toutes écrites en Rust et ont accès à une base de données PostgreSQL pour permettre aux tâches d’arrière-plan d’avoir une base de données persistante. Voici quelques exemples :
- * AbuseIPDB
- * AlienVault OTX
- * Shodan
- * InternetDB
- * VirusTotal
- * HaveIBeenPwned
- * PhishTank
- * OpenPhish
- * HybridAnalysis
- * MalShare
- * MalwareBazaar
- * Megatron
- * URLhaus
- * URLScan
- * WaybackMachine
- * Certification Transparency
- * Google Safe Browsing
- * Enregistrements DNS bruts et le reversement DNS
- * Enregistrements WHOIS bruts
Fournisseurs
Les sources sont organisées en fonction des fournisseurs de sources. Un fournisseur est un groupe de sources liées les unes aux autres, généralement par le même auteur ou la même entreprise. La configuration effectuée au niveau du fournisseur prévaut sur la configuration effectuée au niveau de la source. Cela permet de centraliser la configuration et la documentation pour toutes les sources d’un fournisseur.
IU
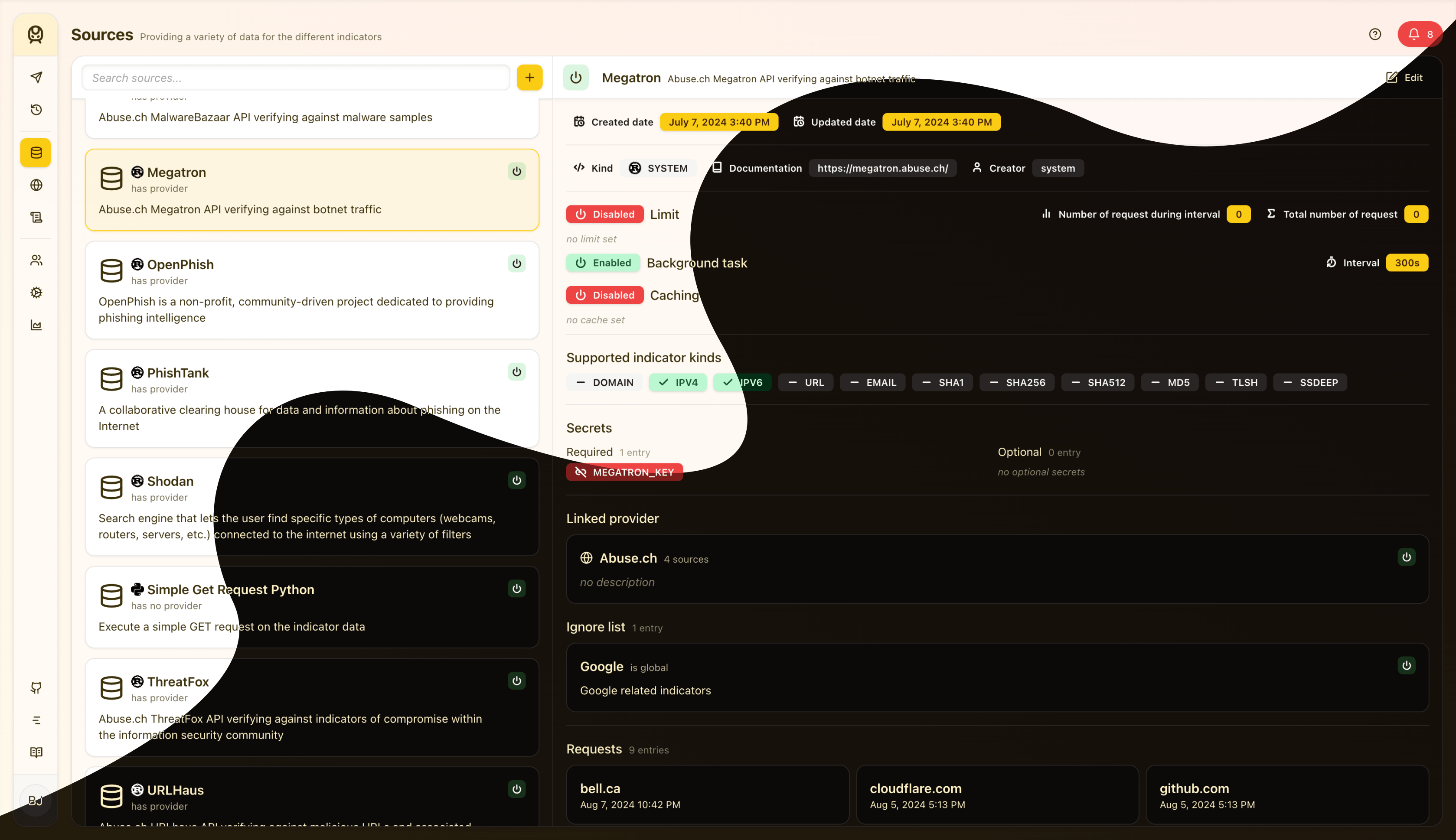
L’interface utilisateur est écrite en React et TypeScript et est une application à page unique (SPA). Elle vous permet d’interroger des données, de voir les résultats et de pouvoir configurer et surveiller l’application. Voici un aperçu de l’application lié à la gestion de sources :
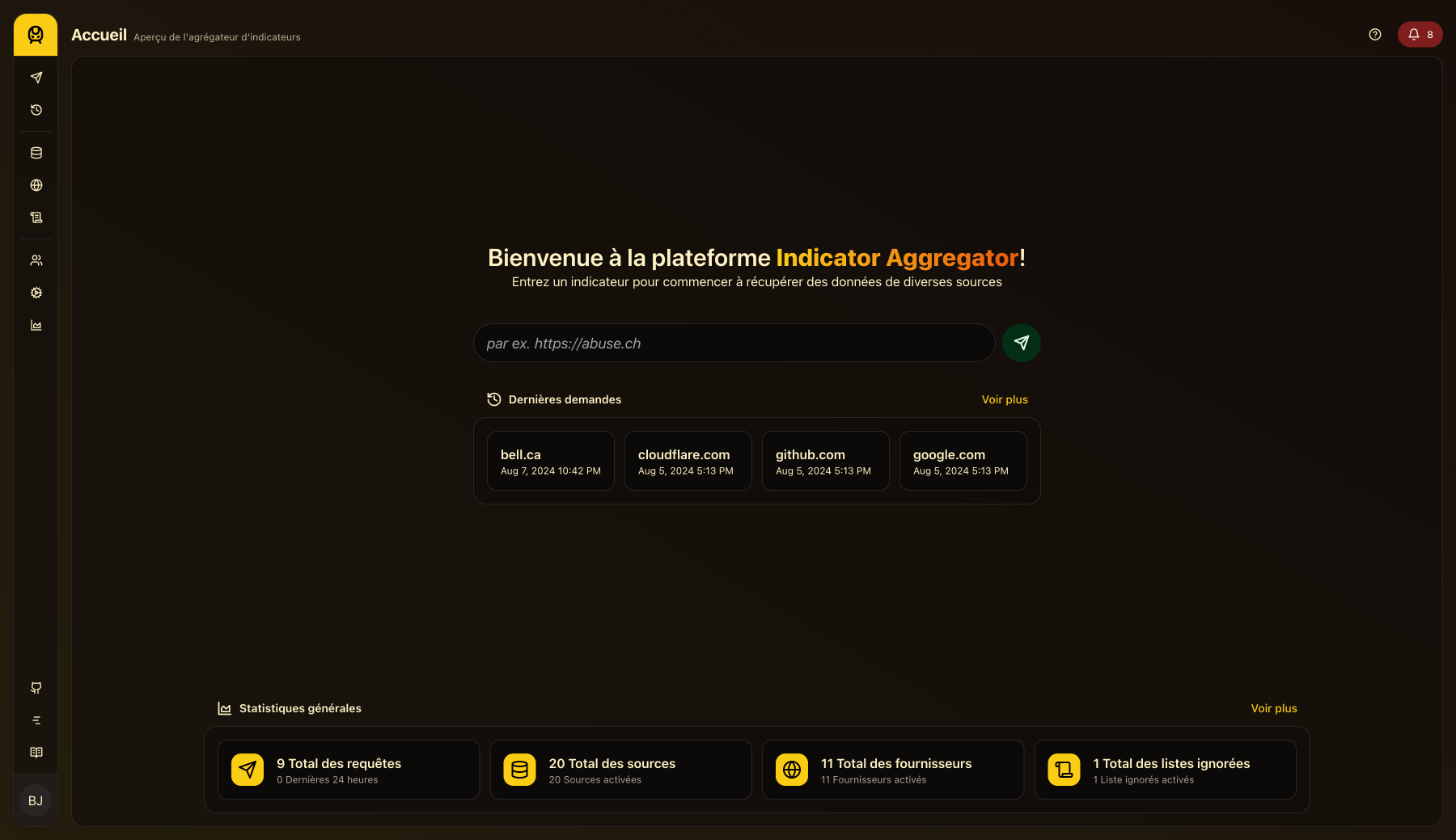
Une autre aperçu de l’interface utilisateur, montrant la page d’accueil en français :
L’interface utilisateur est construite à l’aide de Tailwind CSS , dont de nombreux composants ont été sélectionnés à partir de shadcn/ui . Les icônes proviennent de Lucide . L’interface utilisateur utilise également l’API de récupération intégrée avec TansStack Query pour gérer l’état de l’application.
J’ai eu un peu de plaisir à réviser l’interface utilisateur et à ajouter des animations avec Framer Motion . Tout est responsive et fait facilement avec TailwindCSS.
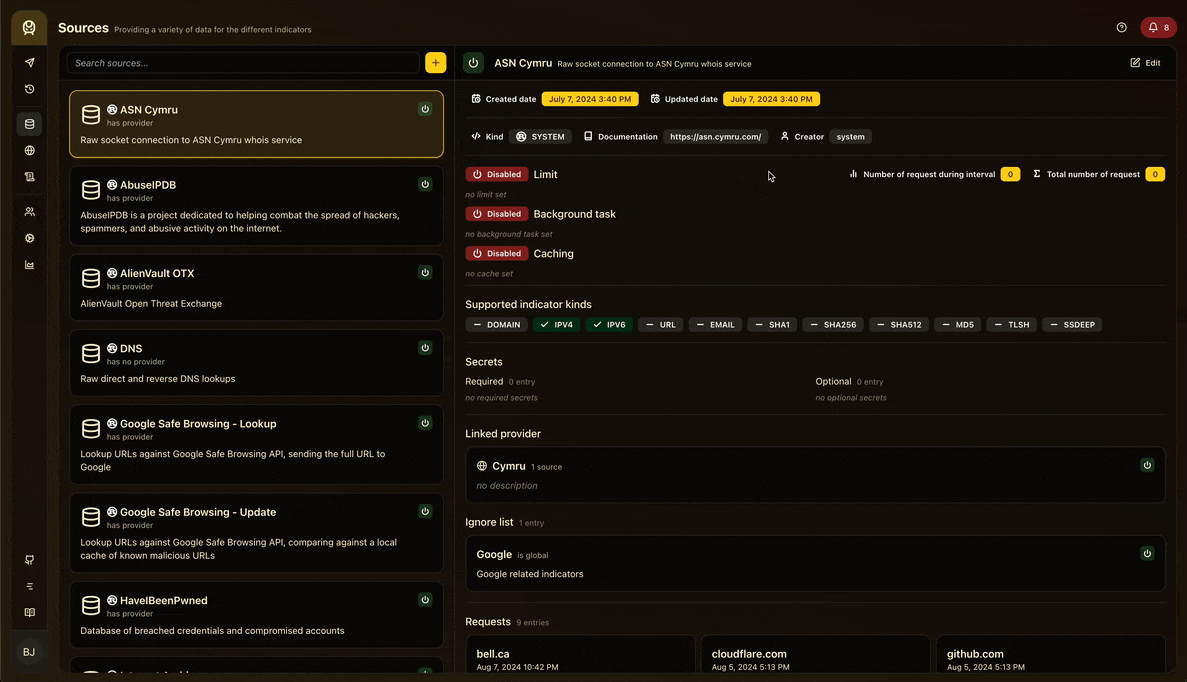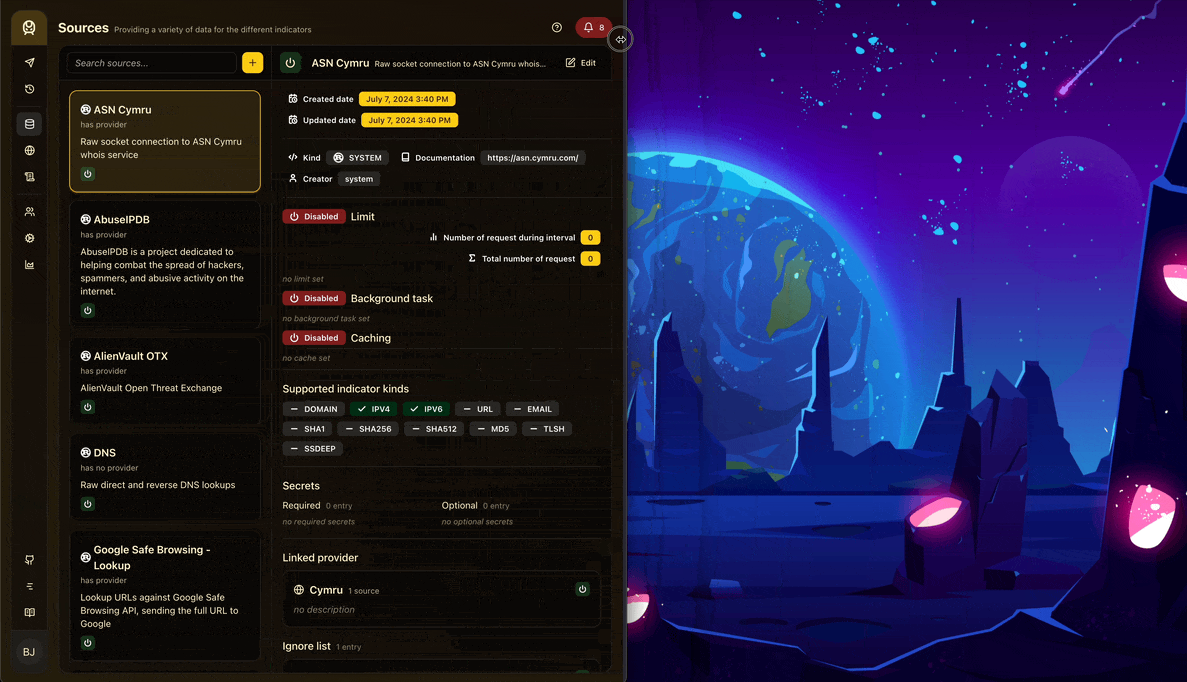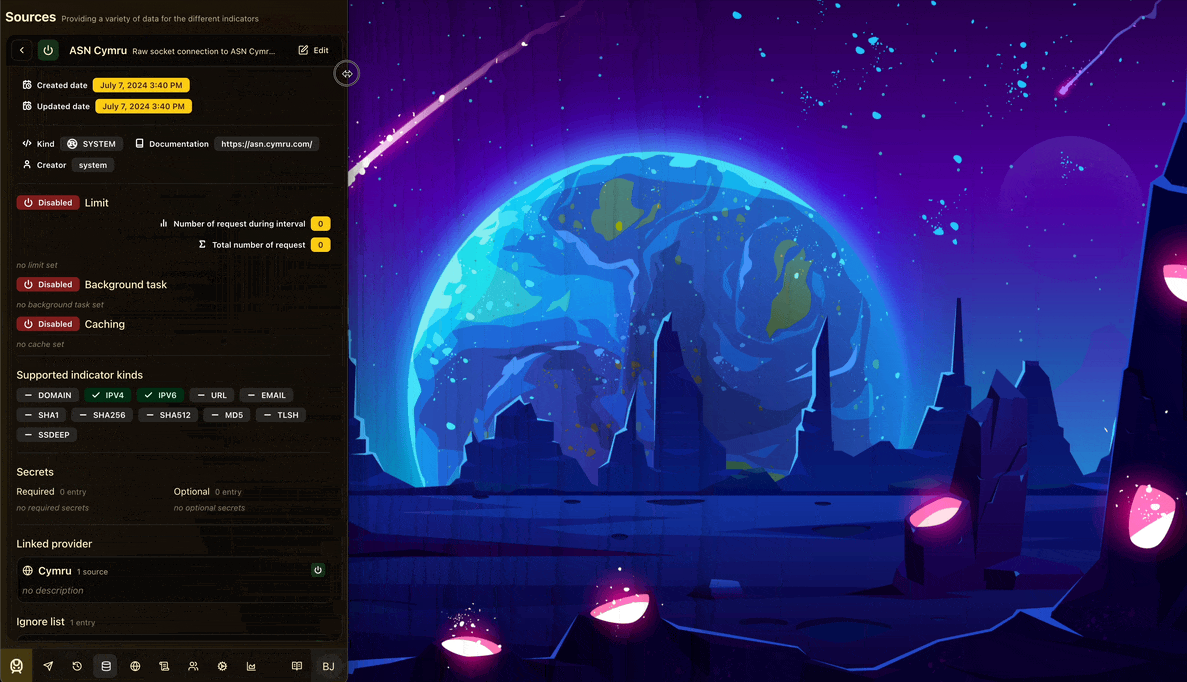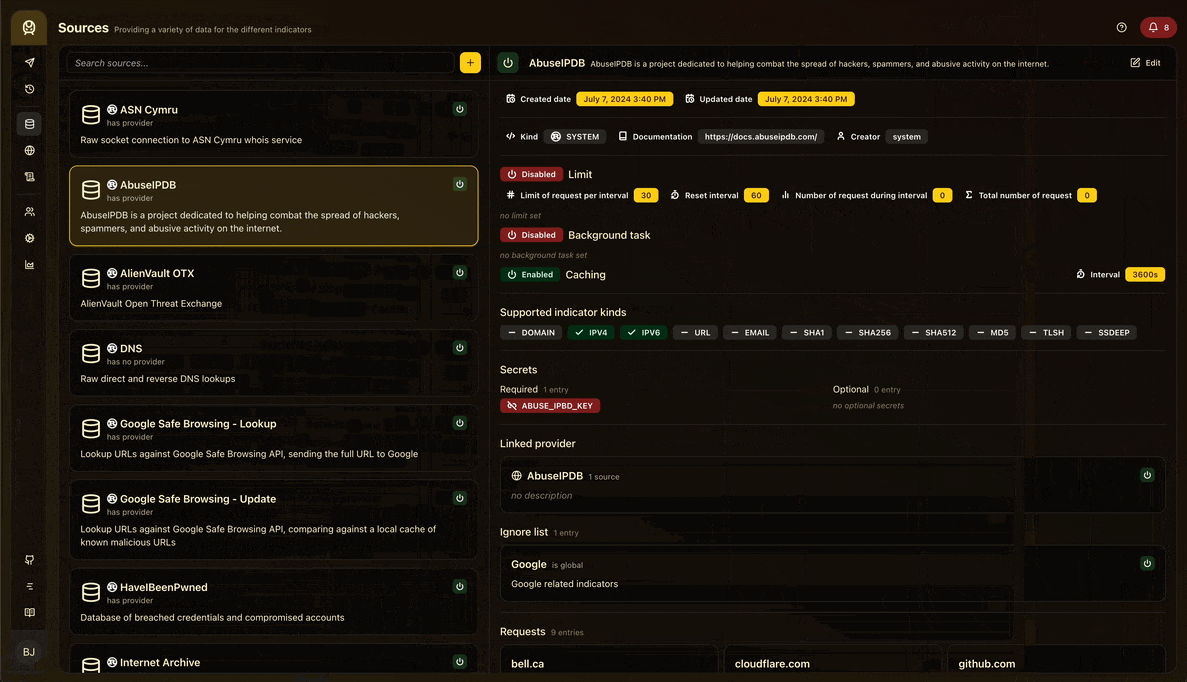
En ce qui concerne la navigation, j’ai voulu expérimenter la nouvelle bibliothèque de routage de Tanner, TanStack Router , qui est un routeur simple et puissant pour React qui s’intègre merveilleusement avec TanStack Query. Elle possède des fonctionnalités puissantes comme le prefetching et le preloading avec un routage basé sur les fichiers et elle est type safe ! Dans l’ensemble, c’est une excellente bibliothèque avec laquelle travailler et je la recommande vivement.
API
L’API est écrite en Rust et est une API REST utilisant Axum . C’est une API simple qui permet à l’interface utilisateur de faire tout ce dont elle a besoin pour configurer le service.
C’est tout pour l’instant, je ferai de mon mieux pour mettre à jour cette page au fur et à mesure.