Travaillé du 2023-03-14 au 2023-09-26
🏷 Mots clés
🚦 Status
En pauseL’objectif était d’avoir un moyen de gérer mes dossiers de code désorganisés. Je ne sais pas si d’autres ont ce problème, mais je commence souvent à travailler sur du code et je ne l’organise pas nécessairement dès le départ. C’est un moyen de gérer ce désordre.
Exploration
Il supporte actuellement l’exploration d’un répertoire jusqu’à ce qu’il trouve un répertoire git ou si l’un des dossiers enfants est un répertoire git. J’ai itéré sur plusieurs façons différentes d’accomplir cela, ce qui peut être vu ci-dessous pour un dossier de ~60GB avec environ 50 répertoires git avec de nombreux dossiers qui ne sont pas des répertoires git pour l’instant. Je comprends que ce n’est pas la meilleure façon de mesurer les performances, mais cela donne une assez bonne idée.
Obtenir uniquement les données relatives à git
L’étape initiale de l’exploration consiste à vérifier si un répertoire est un dépôt git ou non. Lorsqu’il y a un dépôt git, il extrait également des informations pertinentes sur le dépôt.
| Tentative | sortie de la commande time | Description |
|---|---|---|
| 1 | 0.18s user 0.19s system 99% cpu 0.378 total | Utilisation d’une approche de profondeur maximale |
| 2 | 0.16s user 0.04s system 99% cpu 0.204 total | Suivant l’algorithme ci-dessous |
Algorithme d’exploration
Il s’agit d’un mélange d’algorithme récursif de recherche en profondeur et de recherche en largeur, en suivant les étapes suivantes :
1. Obtenir une liste des sous-répertoires et vérifier s'ils ont git (largeur)
1. si oui, descendre dans les répertoires qui n'ont pas git (profondeur)
1. reprendre à l'étape 1 pour chaque répertoire
2. si non, arrêterObtenir toutes les données pertinentes
Cette étape est un peu plus approfondie, elle permet d’obtenir un peu plus d’informations et de données intéressantes. C’est aussi l’étape qui prend le plus de temps.
- * étape d’exploration (temps du tableau précédent)
- * taille totale des octets (plus précis que du -sh)
- * tous les langages de programmation utilisés via tokei
- * lire README.md
| Tentative | sortie de la commande time | Description |
|---|---|---|
| 1 | 16.07s user 31.78s system 126% cpu 37.782 total | Obtenir des données de tous les répertoires |
| 2 | 5.36s user 11.16s system 107% cpu 15.338 total | Récupérer les données des répertoires feuilles |
| 3 | 5.41s user 10.59s system 94% cpu 16.971 total | Récupérer les données des répertoires feuilles + addition de la taille |
| 4 | 5.71s user 15.29s system 311% cpu 6.742 total | Récupérer les données des répertoires feuilles + addition de la taille + parallélisation |
| 5 | 5.51s user 4.18s system 564% cpu 1.717 total | Même chose que précédemment sans calculer de taille… |
La parallélisation est effectuée avec rayon , ce qui simplifie encore le code. D’après les données ci-dessus, il semble que le principal facteur de blocage soit l’exploration des fichiers à partir de tokei. J’ai essayé d’améliorer cette étape sans succès.
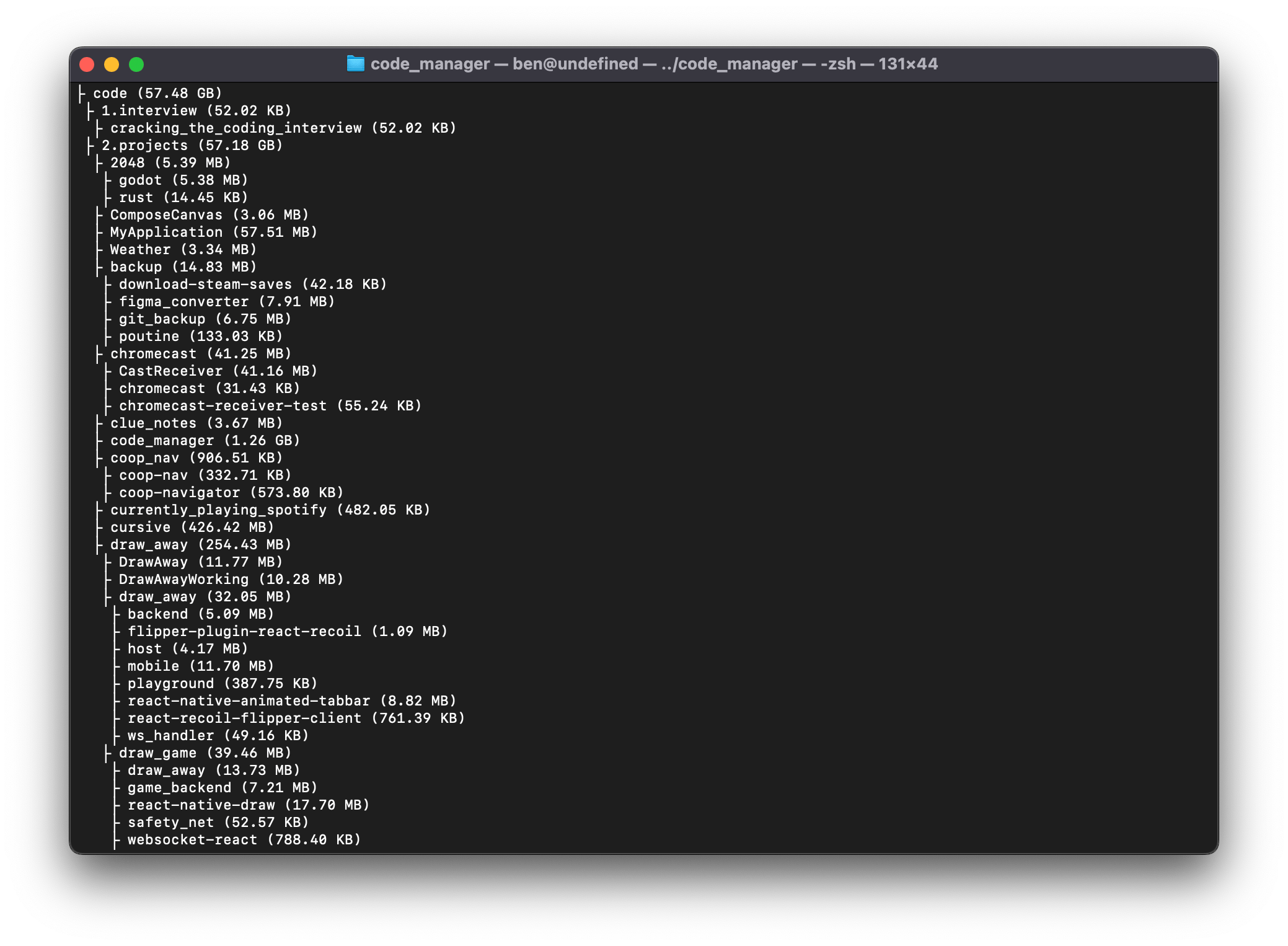
Exemple de sortie
Voici un exemple de sortie, n’affichant que la taille du fichier et le chemin/ficher relatif :
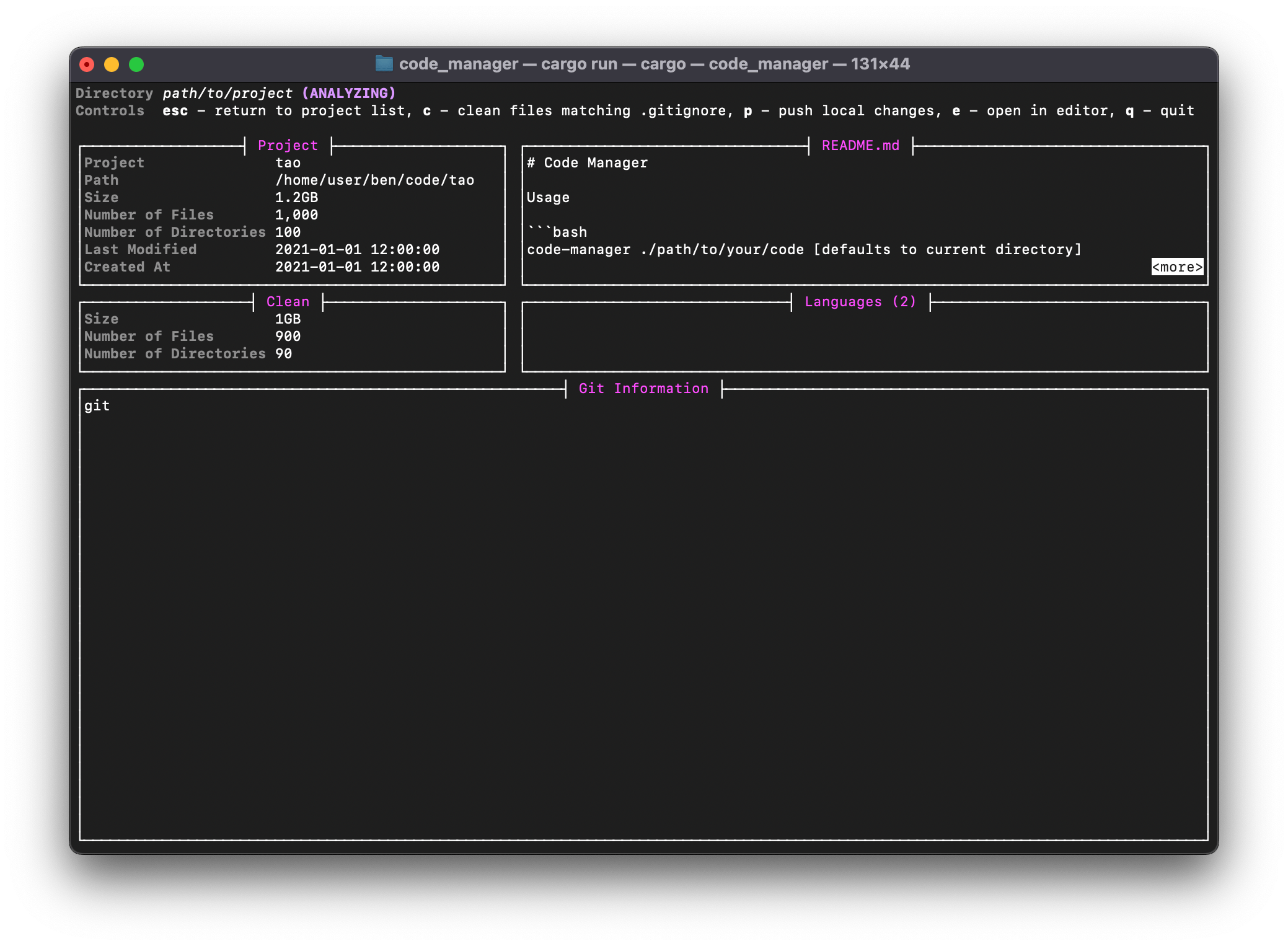
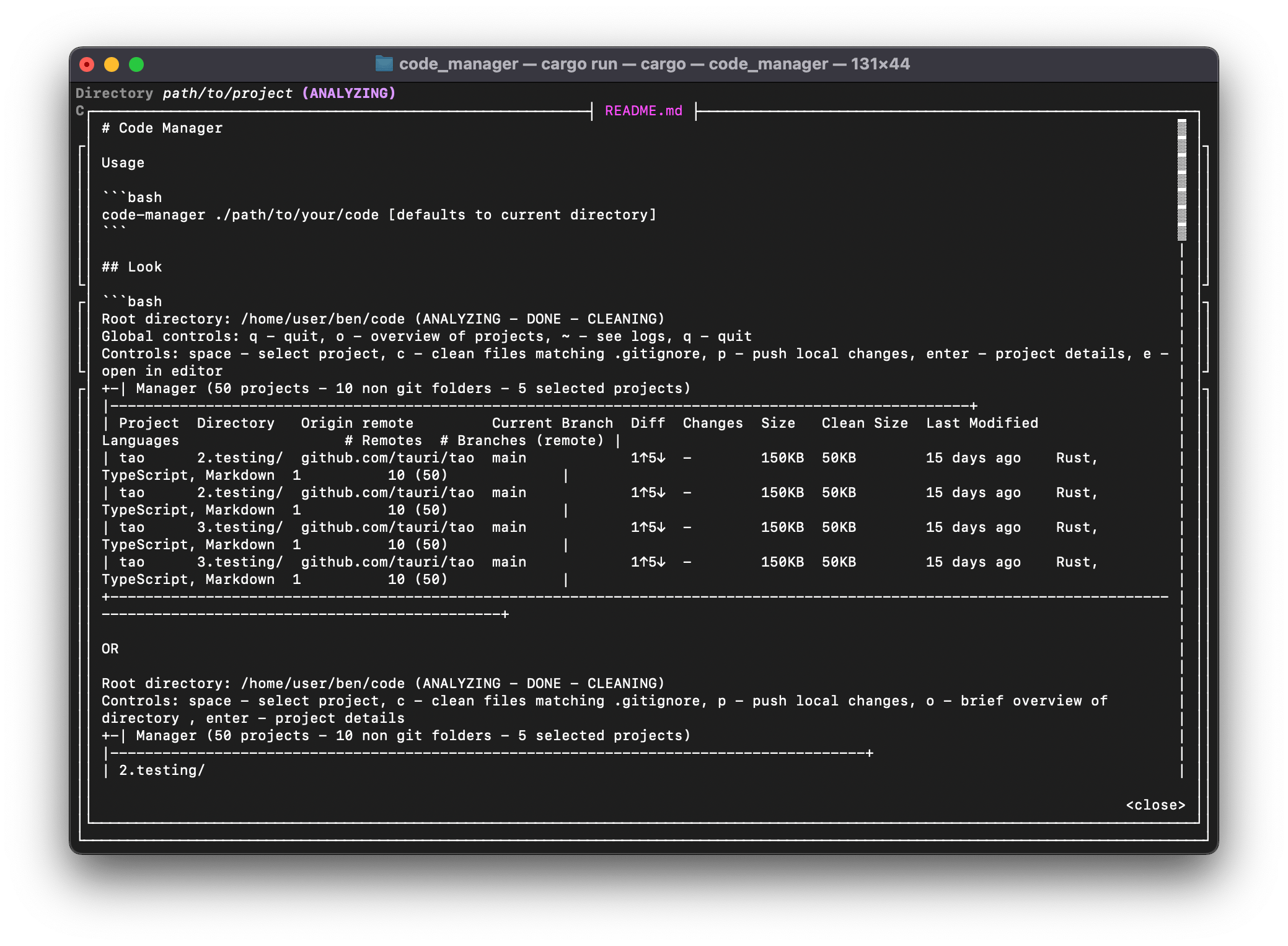
CLI
J’avais commencé à mettre en place un CLI avec cursive , mais je ne l’ai jamais terminé. Voici quelques exemples de ce à quoi il ressemble actuellement :