A Ransomware behavior detection microservice using machine learning and Windows SYSMON logs with an accuracy of 99.18%, a precision of 98.29%, and a recall of 98.85%.
Description
This project was my capstone project for my Software Engineering bachelor at the University of Ottawa with Bell Canada as our client. I worked on this project with Zainab Al Showely.
Architecture
Here’s the overall architecture of the project:


Everything relies on Kafka for the flow of data in the microservice. Logs are sent from the client to a specific Kafka topic (can be done with Winlogbeat ) on a remote server.
On the server, the machine learning service is processing logs at a set interval (defaults to 30 secs) and analyzes the logs from a longer interval (defaults to 10 minutes) in the past. It uses Spark and a Random Forest model trained with a SYSMON dataset, which can be found here . If logs are detected as malicious, they are passed along to the malicious Kafka topic, where our Bell will do the appropriate actions to lock down this threat.
This is the architecture used for testing logs/training a new model. It’s a pretty generic machine learning process.

CI/CD
Our client uses OpenShift servers, so we decided to dockerize everything, making it easy to run and develop. GitHub Actions are used to lint, run tests, and build the Docker image.
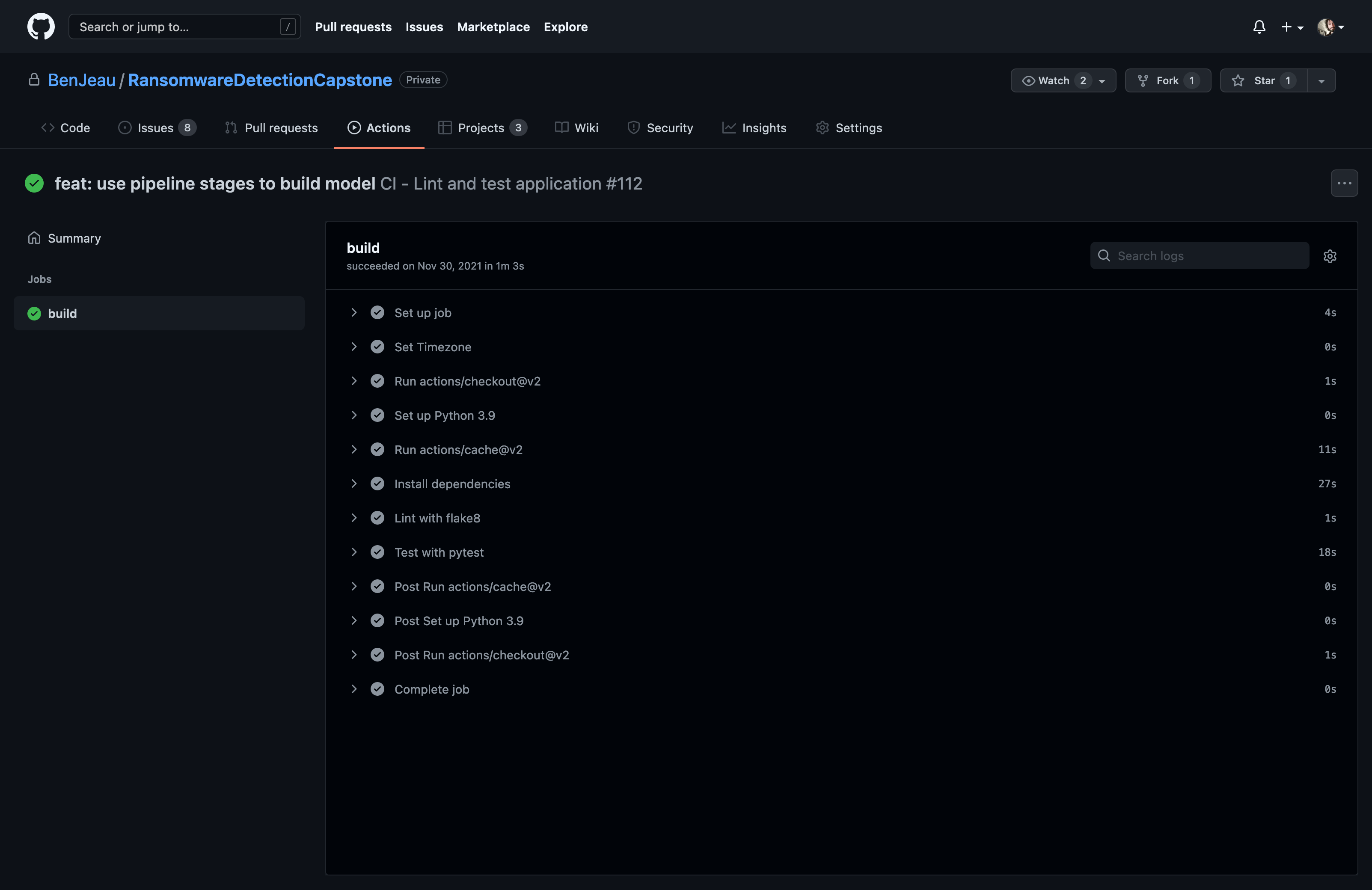
Once the images are built, they are stored in a private GitHub Container Registry, for them to be used by our client.
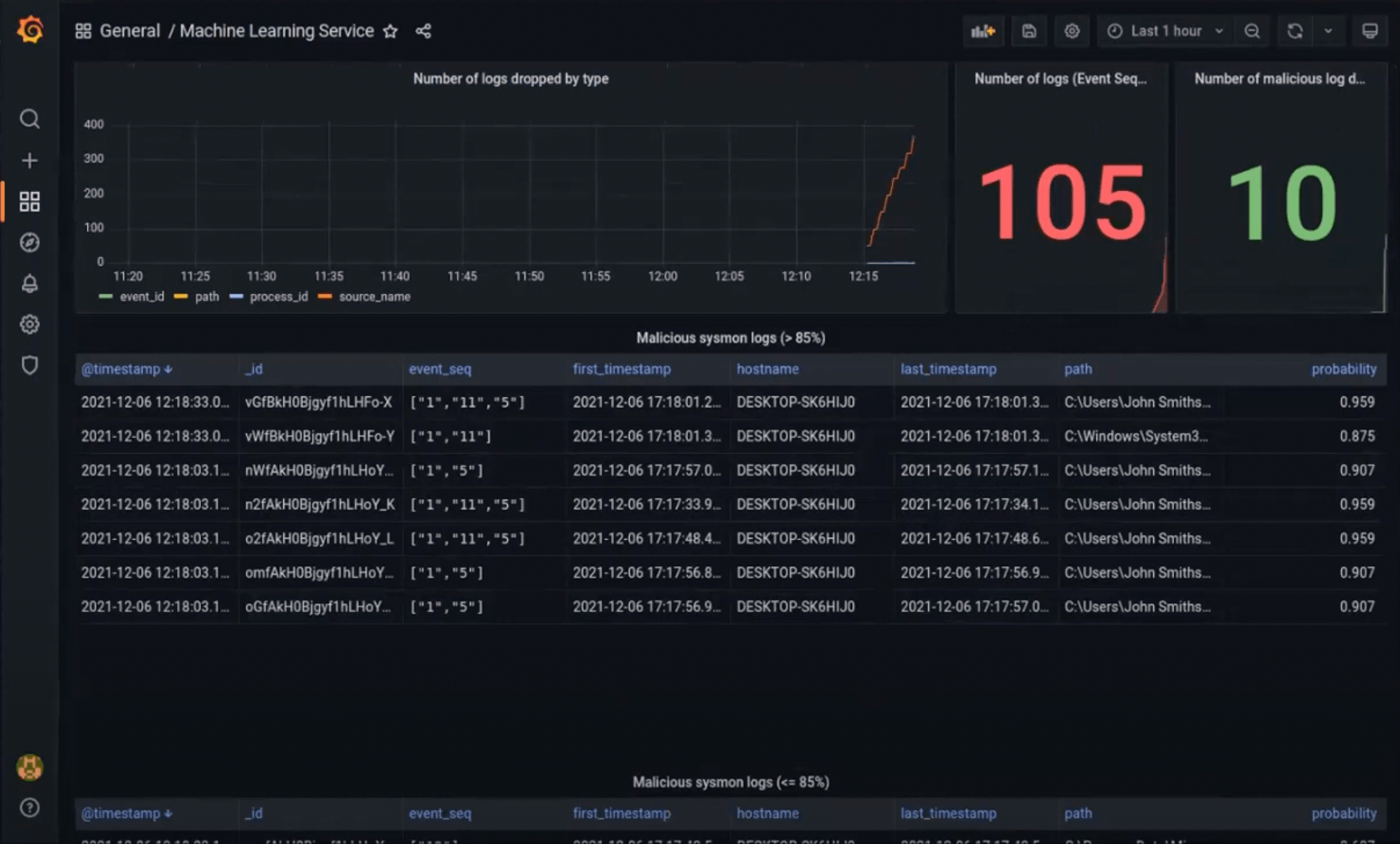
Monitoring
Since this application is mostly developer/analyst facing, we wanted to make it easier for them to interface with our microservice and make their lives easier. This is why we built a custom Grafana dashboard where you can take a quick glance at the analyzed logs, alongside the malicious ones (if there are some).
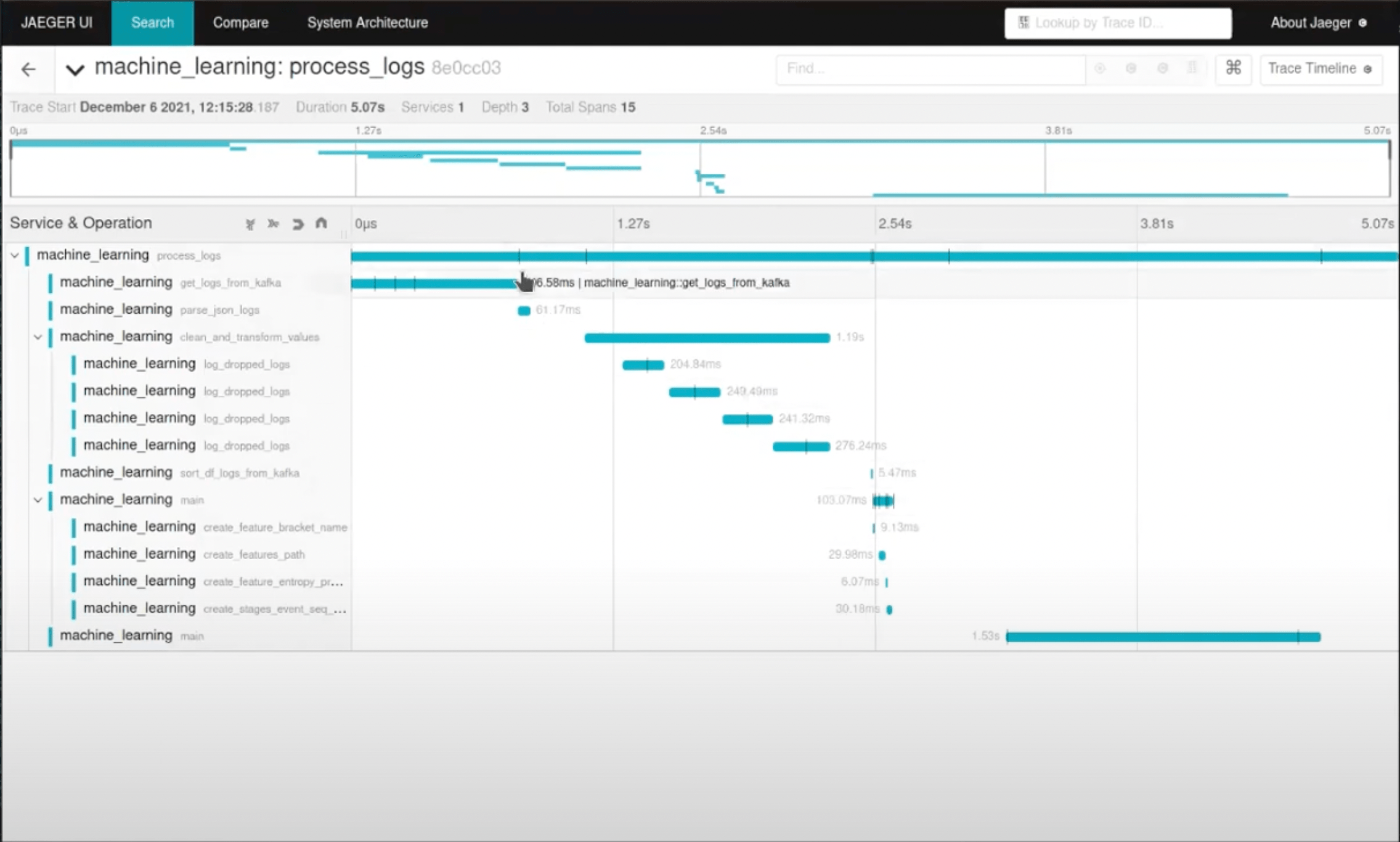
Tracing
Since Ransomware is time critical, we wanted our microservice to be as fast as possible and we also wanted to be able to detect any slow parts in our project. We implemented Jaeger tracing to view the time spent in the functions of our code alongside with logs.
We created a simple Python decorator where it would create a new span for the function and link any logs to that most active span. With the decorator created, to track a function, it’s as simple as prepending the following to the function.
@traceOr
@trace(service="train_model")Improvements
Since we had to pivot from PROCMON logs to SYSMON logs in the middle of our project, we lost some time modifying all of our created features.
In addition, the model may be biased since we didn’t have a lot of data and with process aggregation (done in the feature generation), we may have ended up with even less data. Hence, a way to improve this would be to get more data to create a new better model.
Demo
Here is the final demo of capstone project explaining the technologies used, how they work, and a small APTSimulator detection demo: