A centralized platform for requesting data from various sources mainly about IOCs (indicator of compromise). This is under active development and I envision it to be as follows.
Why centralized?
Centralizing external requests and responses allows for:
- * a normalized request handling (rate limiting, caching, proxying, …)
- * a common response format (error, success, timeouts,…)
- * a centralized caching mechanism
- * a global ignore list
- * built-in limit and quota management
- * secret management
- * background tasks
- * metrics/logs
- * authentication
By having all of these already built, creating a source is as simple as configuring it and writing the code needed to correlate the data. I’ve seen in my field many different ways this was handled, many of which were overly complicated due to:
- * having duplicated code
- * having multiple disconnected microservices (while it may seem like a good idea, it’s not)
- * having no centralization on any of the above
Request data
The data you can query about (IOCs) can vary by its kind, the most popular being:
- * IP addresses
- * Domains
- * URLs
- * Hashes (MD5, SHA1, SHA256, SHA512, TLSH, SSDEEP, …)
- * File names
- * Emails
- * Usernames
- * Names
- * Phone numbers
Indicator Aggregator is not a platform to store and track IOCs, but rather a platform that can be used to get enhanced information about them and have a centralized place to store the data of various data sources.
Sources
Sources can vary in their shape and form. They can be statically written in Rust or dynamically either in Python or JavaScript without needing to recompile the whole application. It can be:
- * an online third-party service
- * an AI process
- * an investigation against OSINT data
- * a simple lookup against a database
- * …
Since sources are just a piece of code being run, your imagination is your limit.
Built-in sources
The built-in sources are all written in Rust having access to a PostgreSQL database to allow for background tasks to have a persistent data store. Here are some examples:
- * AbuseIPDB
- * AlienVault OTX
- * Shodan
- * InternetDB
- * VirusTotal
- * HaveIBeenPwned
- * PhishTank
- * OpenPhish
- * HybridAnalysis
- * MalShare
- * MalwareBazaar
- * Megatron
- * URLhaus
- * URLScan
- * WaybackMachine
- * Certification Transparency
- * Google Safe Browsing
- * Raw DNS records and reverse DNS
- * Raw WHOIS records
Providers
Sources are organized by source providers. A provider is a group of sources that are related to each other, usually by the same author or company. Configuration done at the provider will override the configuration done at the source level. This allows for a centralized configuration and documentation for all sources of a provider.
UI
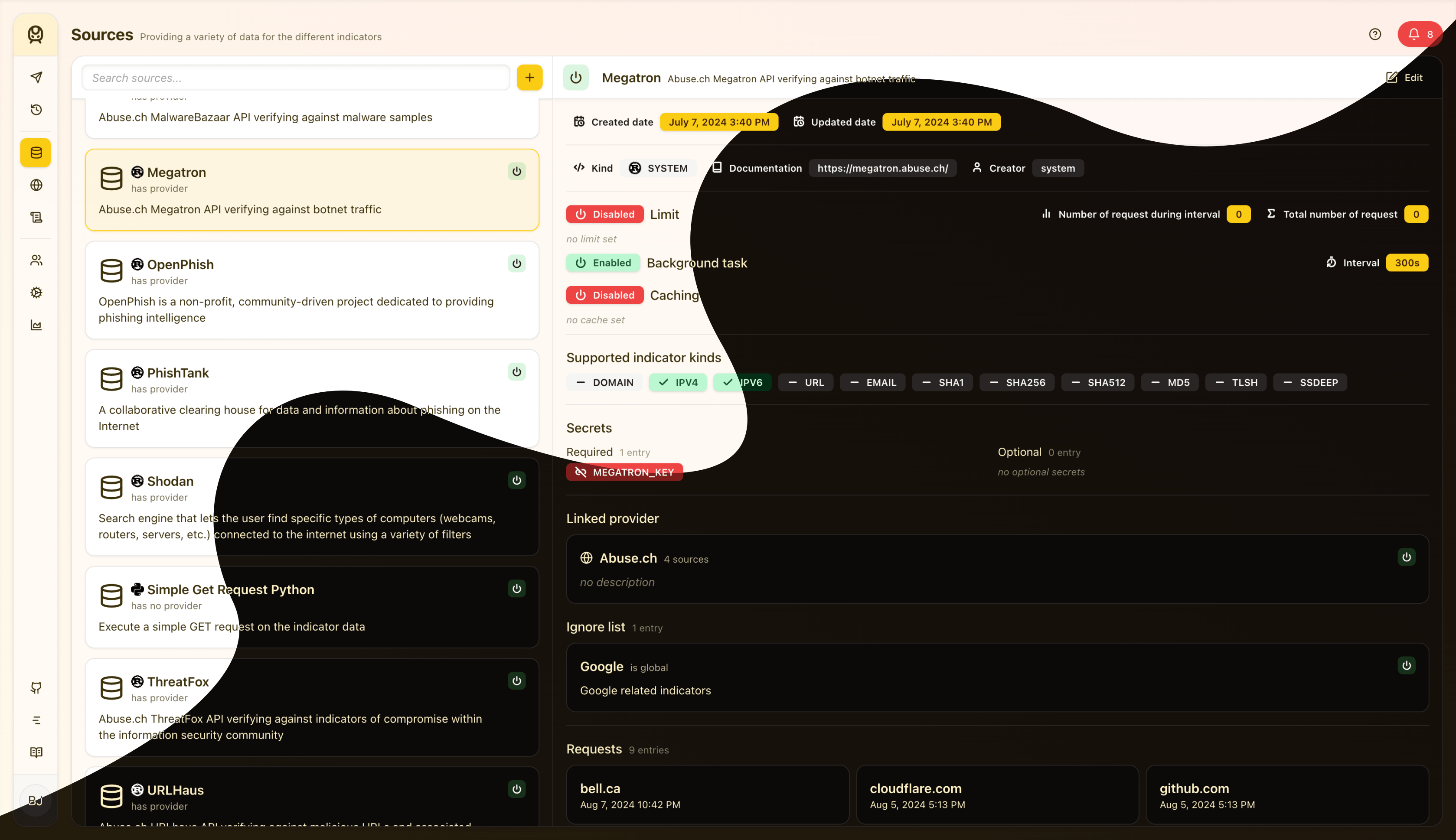
The UI is written in React and TypeScript and is a single page application (SPA). It allows you to query data, see the results, and to be able to configure and monitor the application. Here’s a peek of the application, the page related to the source management:
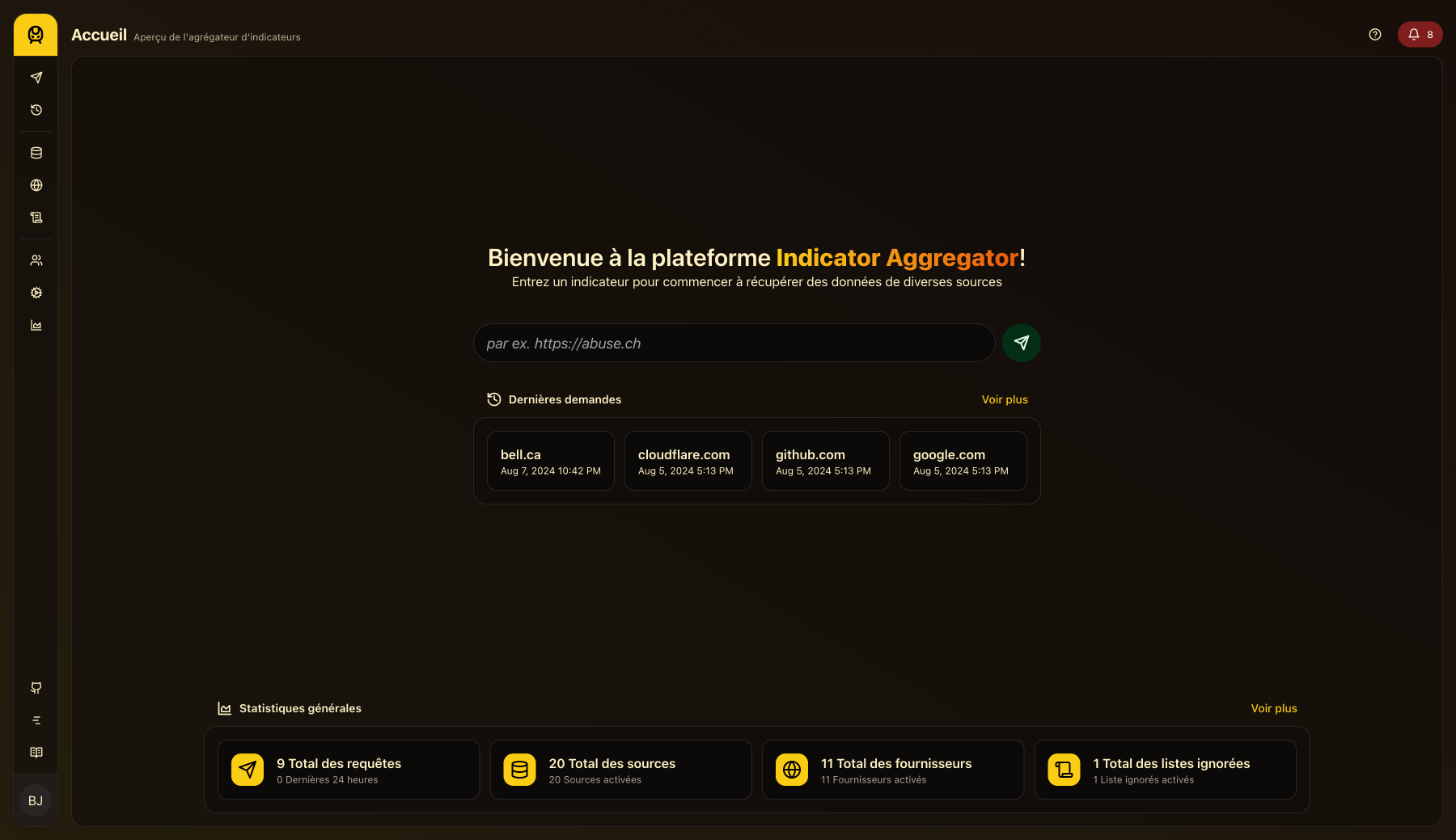
Another peek at the UI, showcasing the homepage in French:
The UI is built using Tailwind CSS where many of the components have been selected from shadcn/ui . Icons are picked from Lucide . The UI is also using the built-in fetch API alongside TansStack Query to manage the state of the application.
I had a bit of fun revamping the UI and adding animations with Framer Motion . Everything is responsive as well and made easily with TailwindCSS.
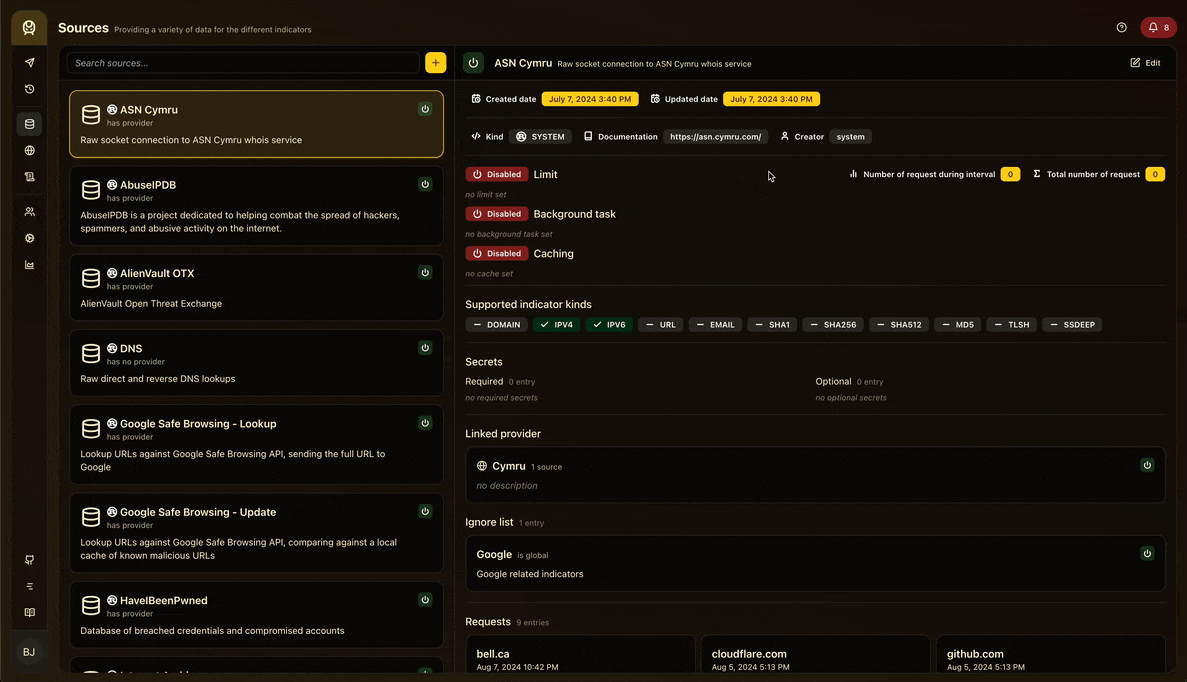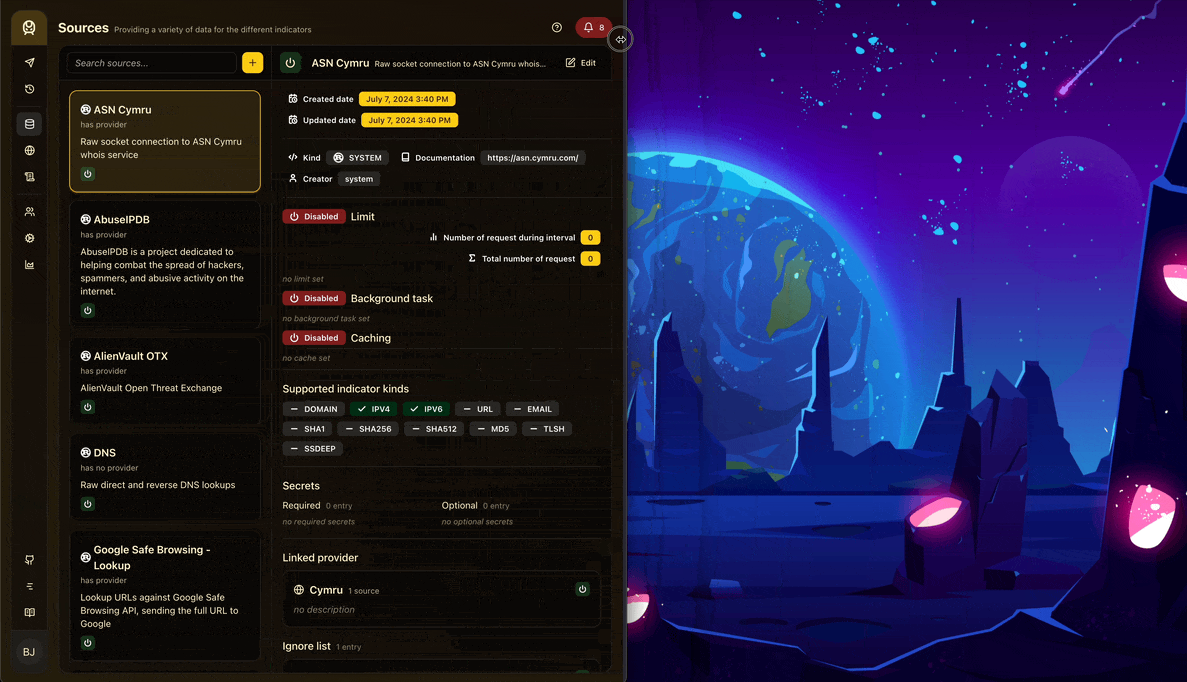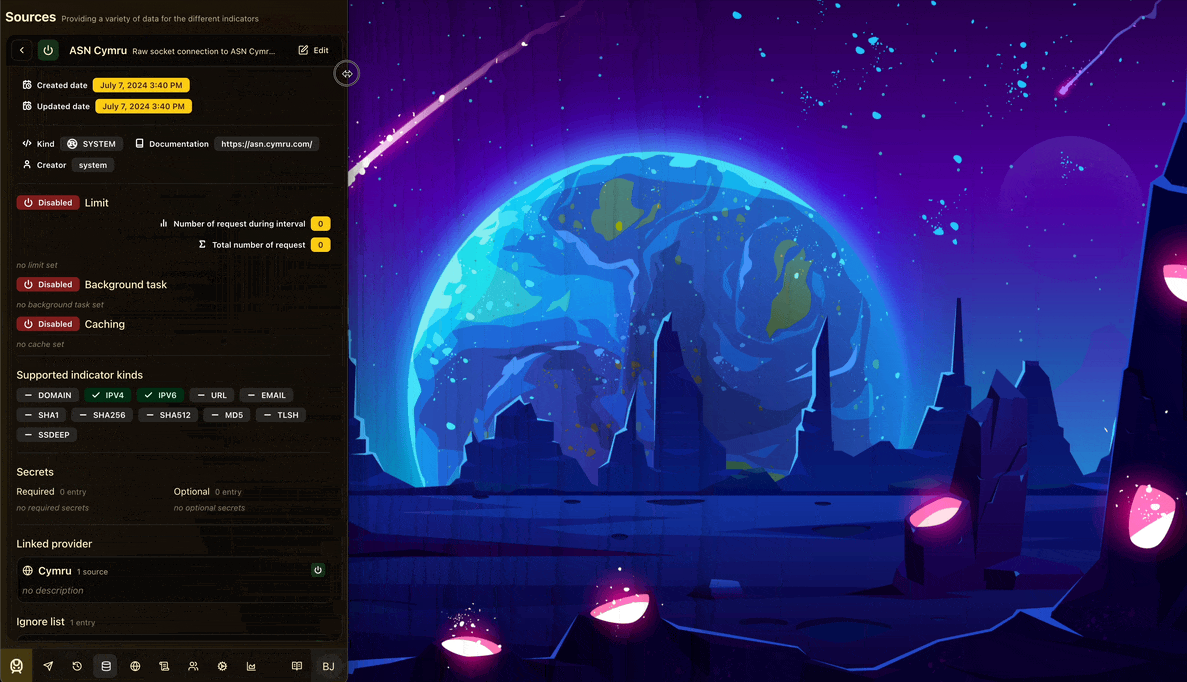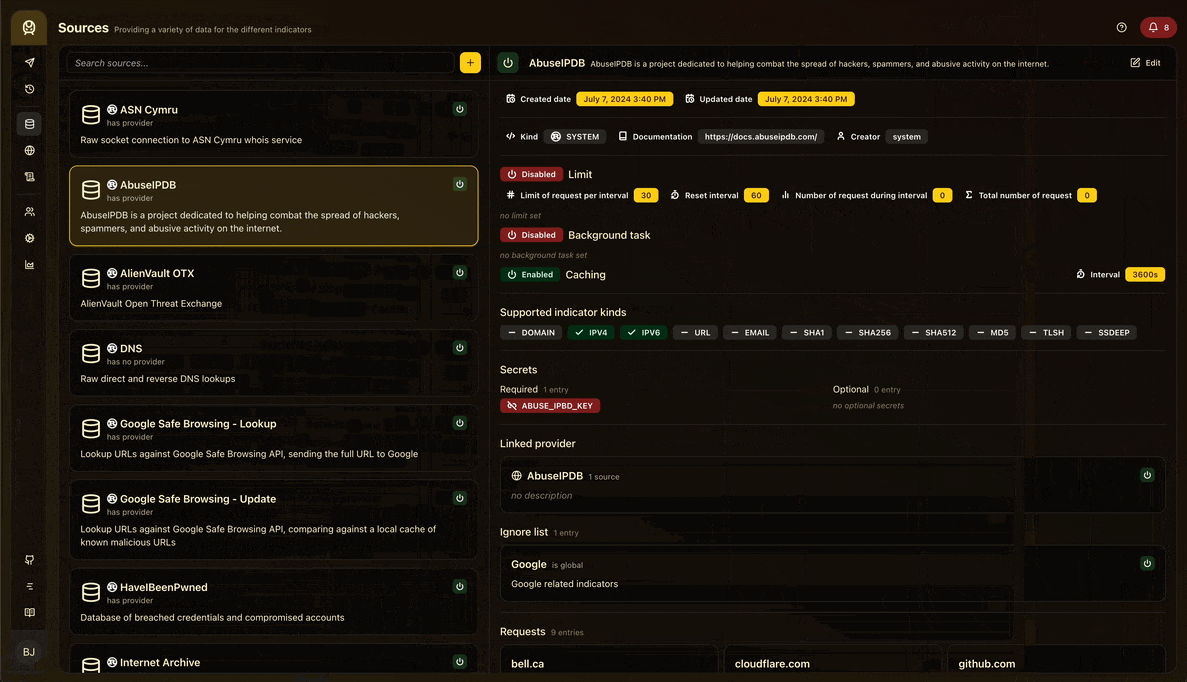
As for routing, I wanted to experiment with Tanner’s new routing library, TanStack Router , which is a simple and powerful router for React that integrates wonderfully with TanStack Query. It has powerful features like prefetching and preloading with file-based routing and is type safe! All-in-all, it’s a great library to work with and I highly recommend it.
API
The API is written in Rust and is a REST API using Axum . It’s a simple API that allows the UI to do all it needs to configure the service.
That’s it for now, I’ll try my best to update this page as I go along.