Worked from 2023-03-14 to 2023-09-26
🏷 Tags
🚦 Status
PausedThe goal of this was to have a way to manage my unorganized code folder dump. Unsure if others have this problem, but I often just start messing with code and don’t necessarily organize it from the start. This is a way to manage that mess.
Crawling
It currently supports crawling a directory until it finds a git repo or if any of the children’s folders are git repos. I’ve iterated over multiple different ways to accomplish this, which can be seen below for a ~60GB folder with around 50 git repos with many folders that are not git repos yet. I understand that this is not the best way to measure performance, but gives a good enough idea.
Getting only git related data
The initial crawling step, checking if a directory is a git repo or not. Whenever there’s a git repo, it also extracts relevant information about the repository.
| Attempt | time output | Description |
|---|---|---|
| 1 | 0.18s user 0.19s system 99% cpu 0.378 total | Using a max depth approach |
| 2 | 0.16s user 0.04s system 99% cpu 0.204 total | Following the algorithm below |
Crawling algorithm
This is a mix of a breadth-first search and depth-first search recursive algorithm, following the steps:
1. Get a list of sub-directories and check if they have git (breadth)
1. if yes, drill down in the non git directories (depth)
1. start back at step 1 for every directory
2. if no, stopGetting all relevant data
This is a bit more thorough, getting a bit more information and interesting data. This is also the step that takes the longest.
- * crawling step (time from the previous table)
- * total byte size (more accurate than du -sh)
- * all programming languages used via tokei
- * read README.md
| Attempt | time output | Description |
|---|---|---|
| 1 | 16.07s user 31.78s system 126% cpu 37.782 total | Getting data from every directory |
| 2 | 5.36s user 11.16s system 107% cpu 15.338 total | Getting data from leaf directories |
| 3 | 5.41s user 10.59s system 94% cpu 16.971 total | Getting data from leaf directories + summing size |
| 4 | 5.71s user 15.29s system 311% cpu 6.742 total | Getting data from leaf directories + summing size + parallelization |
| 5 | 5.51s user 4.18s system 564% cpu 1.717 total | Same as before without calculating any size… |
Parallelization is done with rayon making the code even simpler. From the data above, it seems like the biggest bottleneck is the file crawling from tokei. I had tried to improve on that step to no avail.
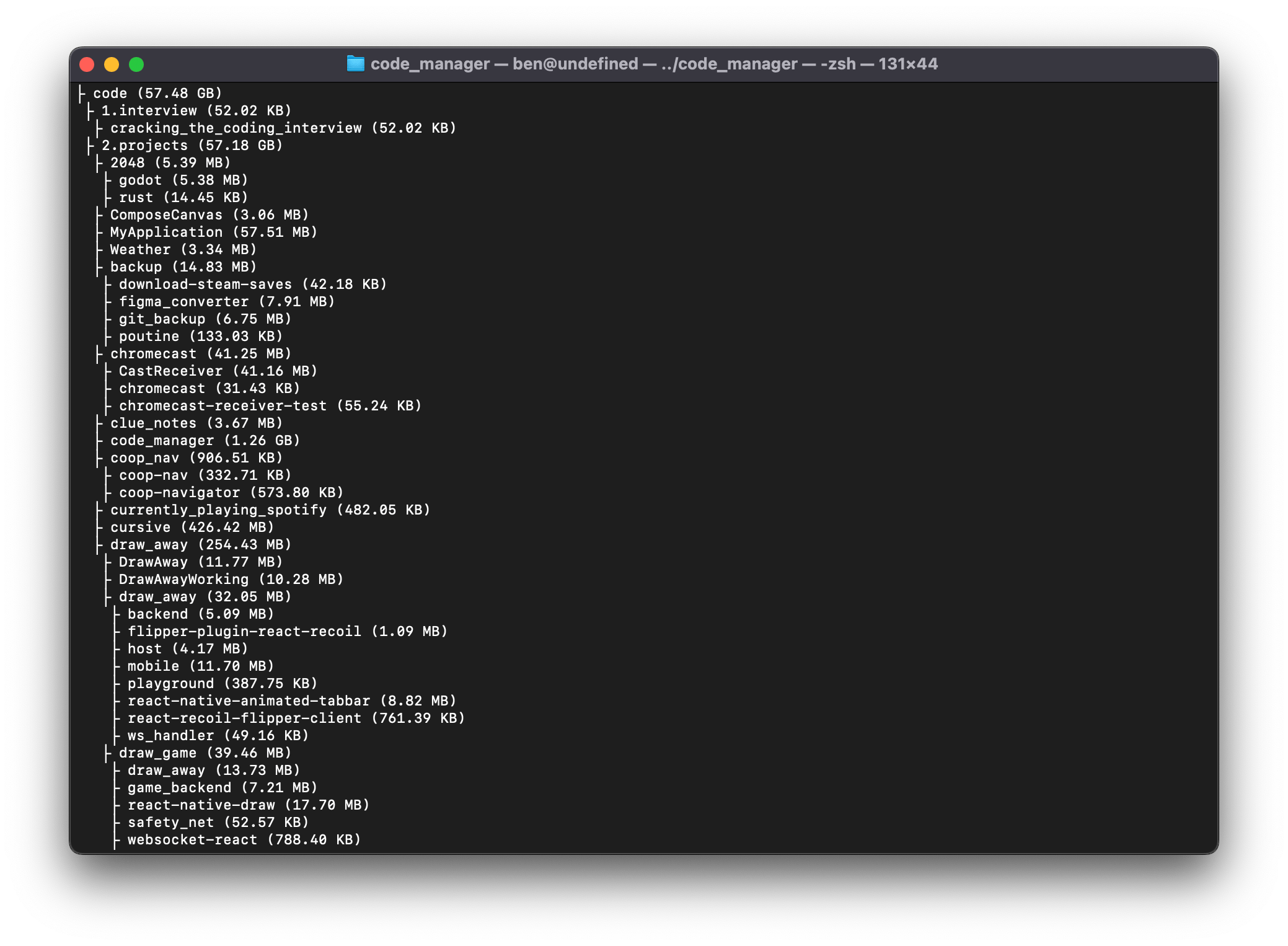
Output example
Here’s a sample of the output, only displaying the file size and relative path/filename:
CLI
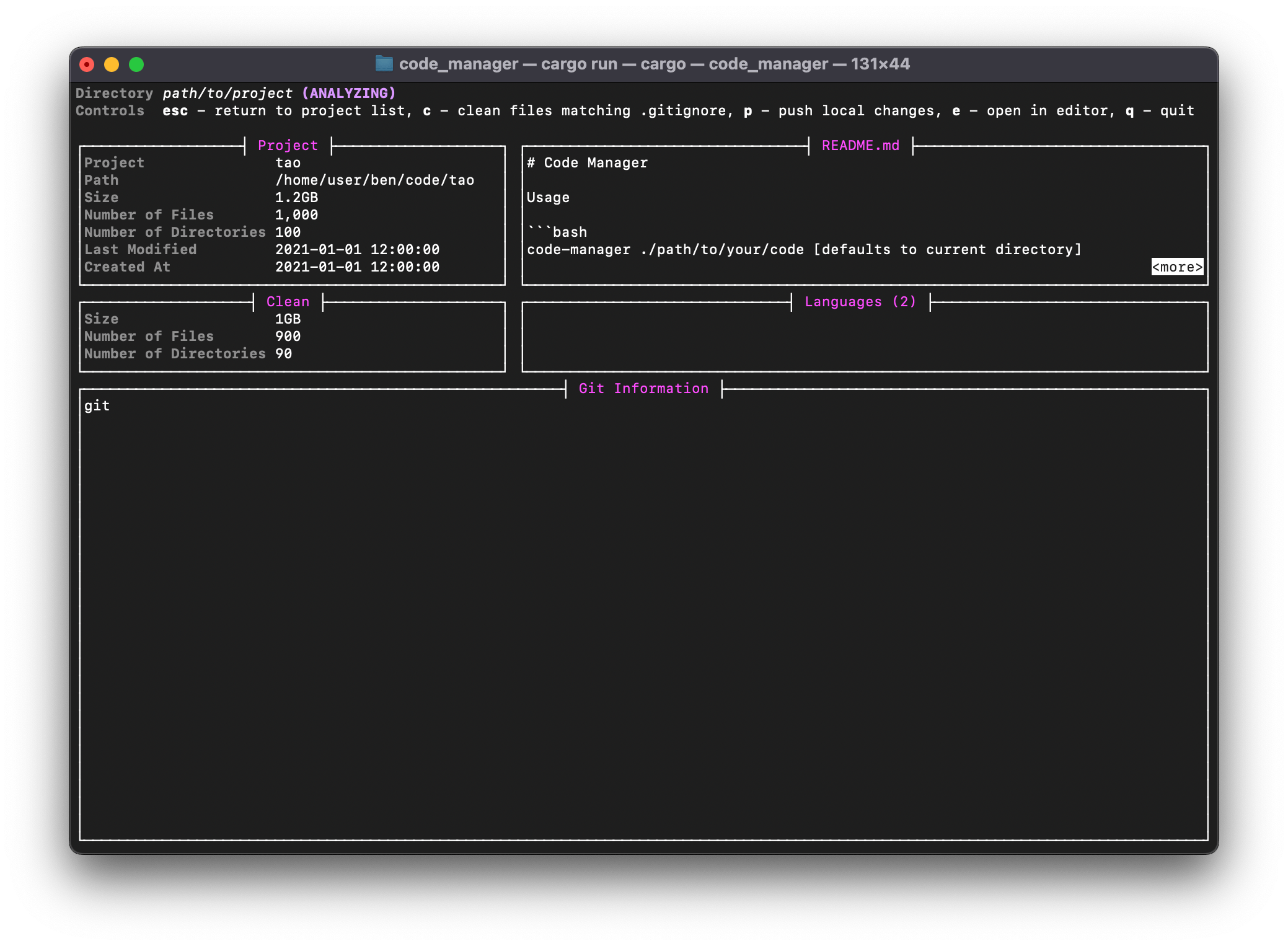
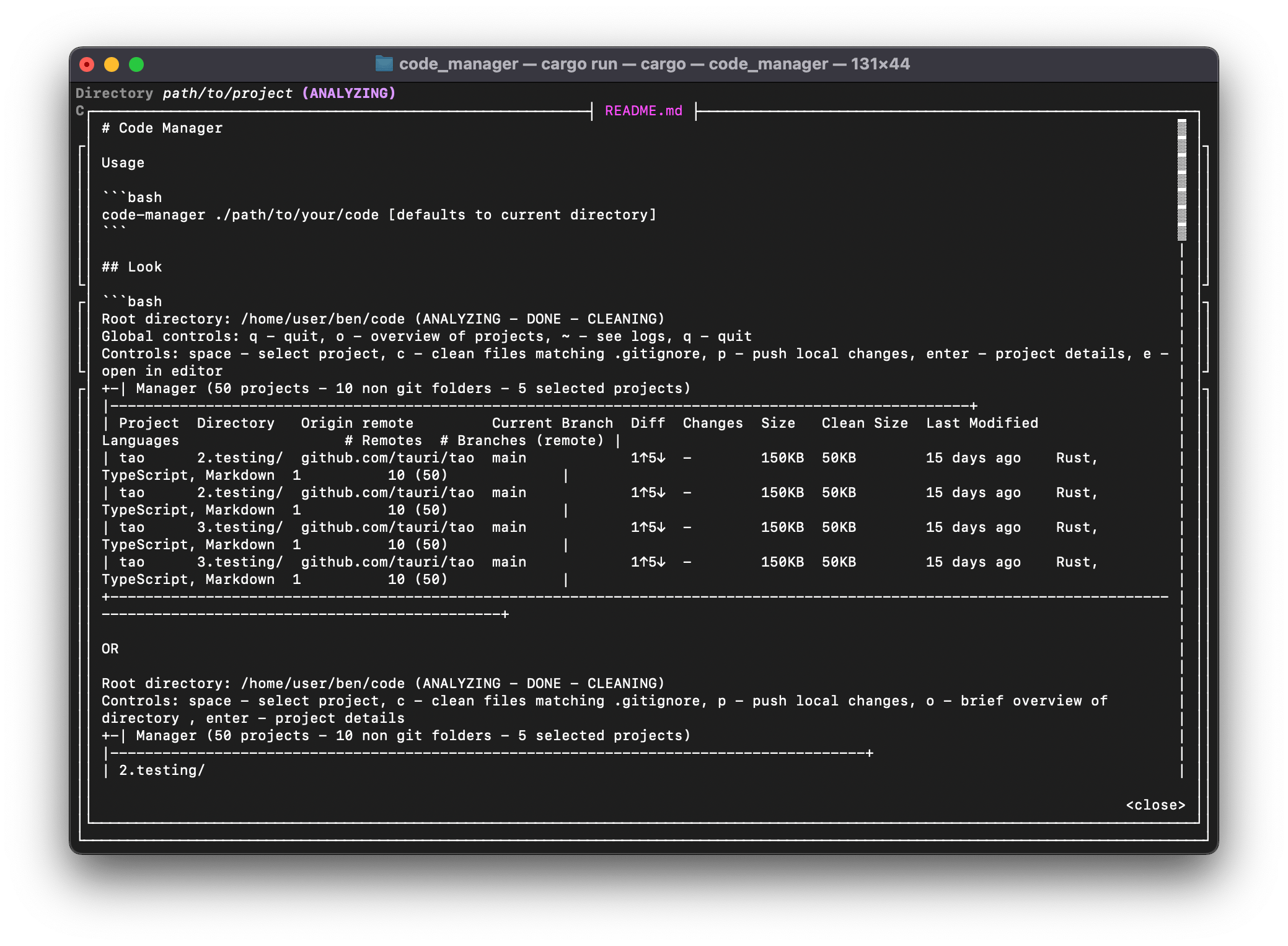
I had started to implement a CLI with cursive , but never finished it. Here’s a few of how it currently looks: